Improving Distributed Gradient Descent Using Reed-Solomon CodesW. Halbawi, N. Azizan R., F. Salehi, and B. Hassibi Submitted to the IEEE Transactions on Information Theory Today's massively-sized datasets have made it necessary to often perform computations on them in a distributed manner. In principle, a computational task is divided into subtasks which are distributed over a cluster operated by a taskmaster. One issue faced in practice is the delay incurred due to the presence of slow machines, known as stragglers. Several schemes, including those based on replication, have been proposed in the literature to mitigate the effects of stragglers and more recently, those inspired by coding theory have begun to gain traction. In this work, we consider a distributed gradient descent setting suitable for a wide class of machine learning problems. We adopt the framework of Tandon et al. 1 and present a deterministic scheme that, for a prescribed per-machine computational effort, recovers the gradient from the least number of machines |
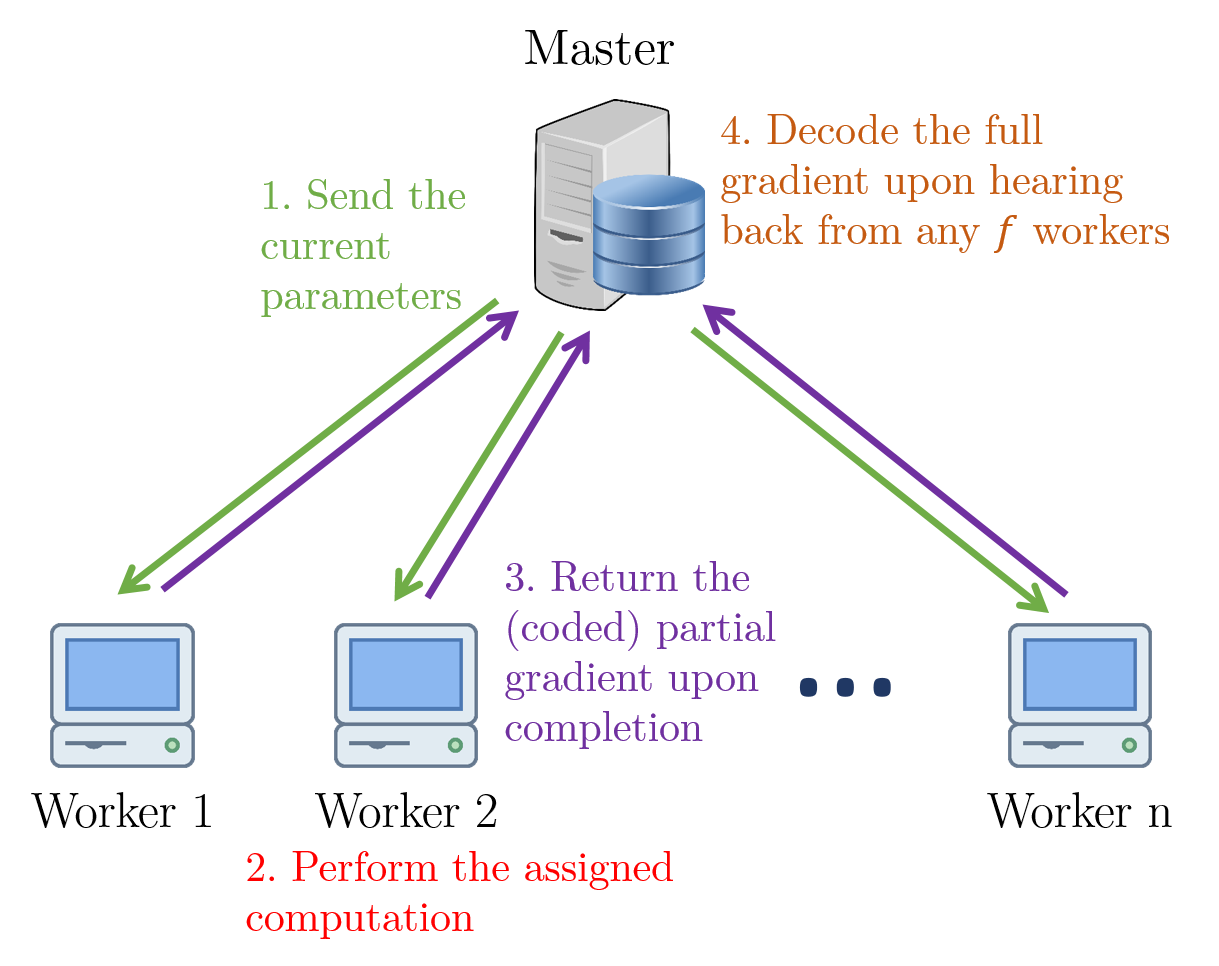
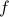 theoretically permissible, via an
theoretically permissible, via an 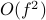 decoding algorithm. The idea is based on a suitably designed Reed–Solomon code that has a sparsest and balanced generator matrix. We also provide a theoretical delay model which can be used to minimize the expected waiting time per computation by optimally choosing the parameters of the scheme. Finally, we supplement our theoretical findings with numerical results that demonstrate the efficacy of the method and its advantages over competing schemes.
decoding algorithm. The idea is based on a suitably designed Reed–Solomon code that has a sparsest and balanced generator matrix. We also provide a theoretical delay model which can be used to minimize the expected waiting time per computation by optimally choosing the parameters of the scheme. Finally, we supplement our theoretical findings with numerical results that demonstrate the efficacy of the method and its advantages over competing schemes.