Stochastic Mirror Descent on Overparameterized Nonlinear ModelsN. Azizan R., S. Lale, and B. Hassibi IEEE Transactions on Neural Networks and Learning Systems, 2021 Most modern learning problems are highly overparameterized, meaning that the model has many more parameters than the number of training data points, and as a result, the training loss may have infinitely many global minima (in fact, a manifold of parameter vectors that perfectly interpolates the training data). Therefore, it is important to understand which interpolating solutions we converge to, how they depend on the initialization point and the learning algorithm, and whether they lead to different generalization performances. In this paper, we study these questions for the family of stochastic mirror descent (SMD) algorithms, of which the popular stochastic gradient descent (SGD) is a special case. Recently it has been shown that, for overparameterized linear models, SMD converges to the global minimum that is “closest” (in terms of the Bregman divergence of the mirror used) to the initialization point, a phenomenon referred to as implicit regularization. Our contributions in this paper are both theoretical and experimental. On the theory side, we show that in the overparameterized nonlinear setting, if the initialization is close enough to the manifold of global optima, SMD with sufficiently small step size converges to a global minimum that is approximately the closest global minimum in Bregman divergence, thus attaining approximate implicit regularization. For highly overparametrized models, this closeness comes for free: the manifold of global optima is so high-dimensional that with high probability an arbitrarily chosen initialization will be close to the manifold. On the experimental side, our extensive experiments on the MNIST and CIFAR-10 datasets, using various initializations, various mirror descents, and various Bregman divergences, consistently confirms that this phenomenon indeed happens in deep learning: SMD converges to the closest global optimum to the initialization point in the Bregman divergence of the mirror used. Our experiments further indicate that there is a clear difference in the generalization performance of the solutions obtained from different SMD algorithms. Experimenting on the CIFAR-10 dataset with different regularizers, |
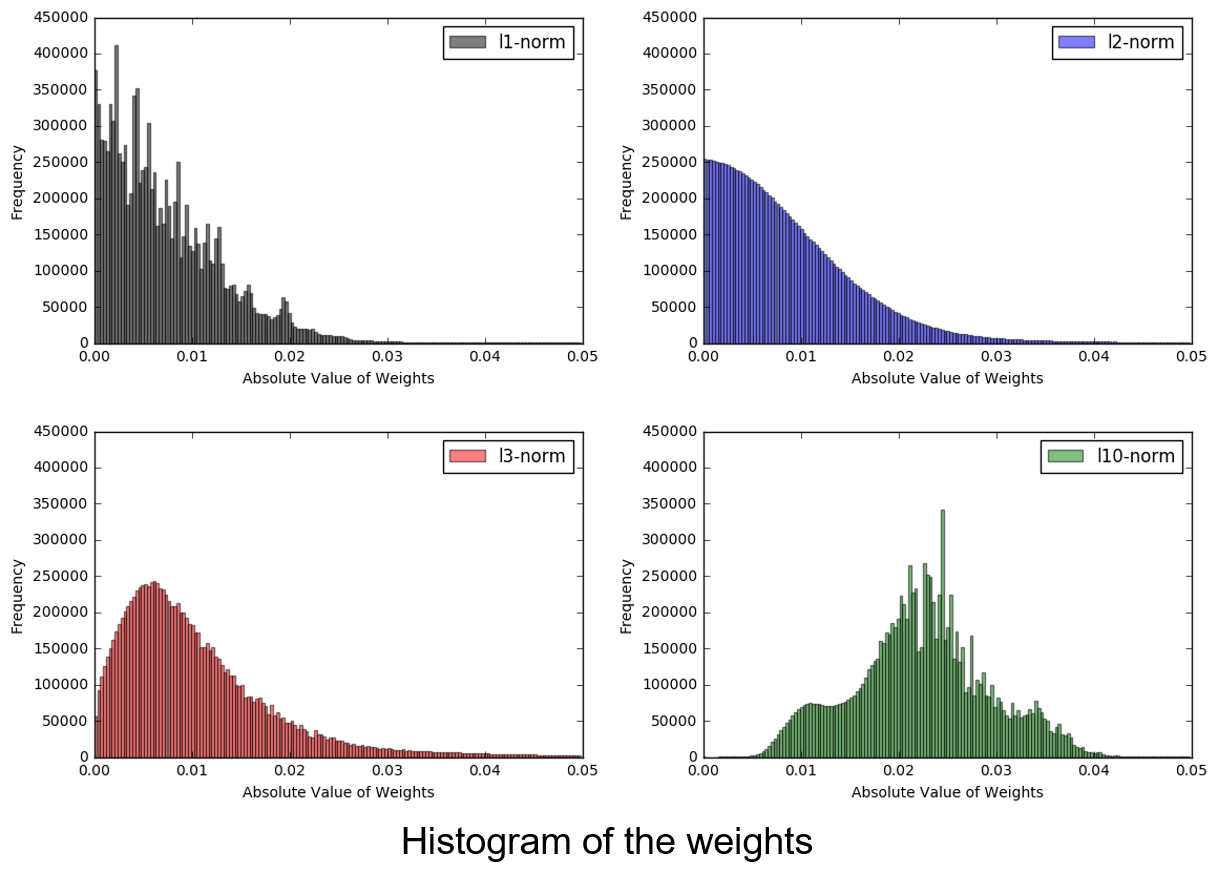
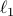 to encourage sparsity,
to encourage sparsity, 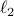 (yielding SGD) to encourage small Euclidean norm, and
(yielding SGD) to encourage small Euclidean norm, and 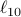 to discourage large components in the parameter vector, consistently and definitively shows that, for small initialization vectors,
to discourage large components in the parameter vector, consistently and definitively shows that, for small initialization vectors,